
Humbak: Samo-Poprawa Modeli Językowych Bez Nadzoru Człowieka
Nowa technika zwana „instruction backtranslation” umożliwia dużym modelom językowym (LLM) poprawę ich zdolności do wykonywania instrukcji bez konieczności dodatkowych adnotacji od ludzi czy zewnętrznych modeli. Badacze z Meta AI opublikowali pracę szczegółowo opisującą tę metodę samo-poprawy (ang. self-alignment).
Podejście to wykorzystuje LLM do generowania „instrukcji” dla nieoznaczonych (ang. unlabeled) tekstów z sieci, a następnie wybiera wysokiej jakości pary instrukcja-tekst do dostrojenia samego siebie. Po dwóch iteracjach ich model o nazwie Humpback wyprzedza wszystkie inne modele LLM w rankingu wykonywania instrukcji.
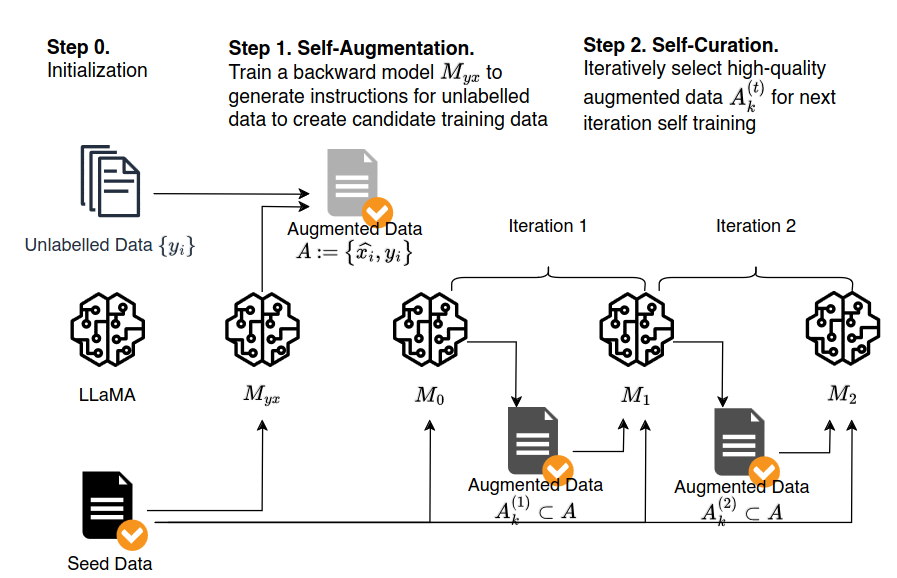
Metoda „Instruction Backtranslation”
Metoda opisana w artykule wygląda następująco:
- Zaczynamy od podstawowego modelu językowego (np. LLaMA), niewielkiego zestawu ludzkich przykładów instrukcja-wynik oraz dużej bazy nieoznaczonych tekstów (strony internetowe).
- Bazowy model jest dostrajany (ang. fine-tune) na danych z niewielkiego zestawu, aby stworzyć model „wsteczny”, który potrafi generować instrukcję na podstawie danego tekstu wynikowego.
- Model wsteczny jest wykorzystywany do generowania poleceń dla każdej nieoznaczonej strony internetowej, tworząc kandydujące pary danych treningowych.
- Bazowy model ocenia jakość każdej pary kandydującej i wybiera tylko pary o najwyższej ocenie.
- Bazowy model jest dostrajany na wybranej wysokiej jakości danych rozszerzonych oraz oryginalnym małym zestawie treningowym.
- Iteracja – ulepszony model ponownie ocenia kandydatów i wybiera lepsze dane, dalej się dostrajając.
Kluczowe wyniki
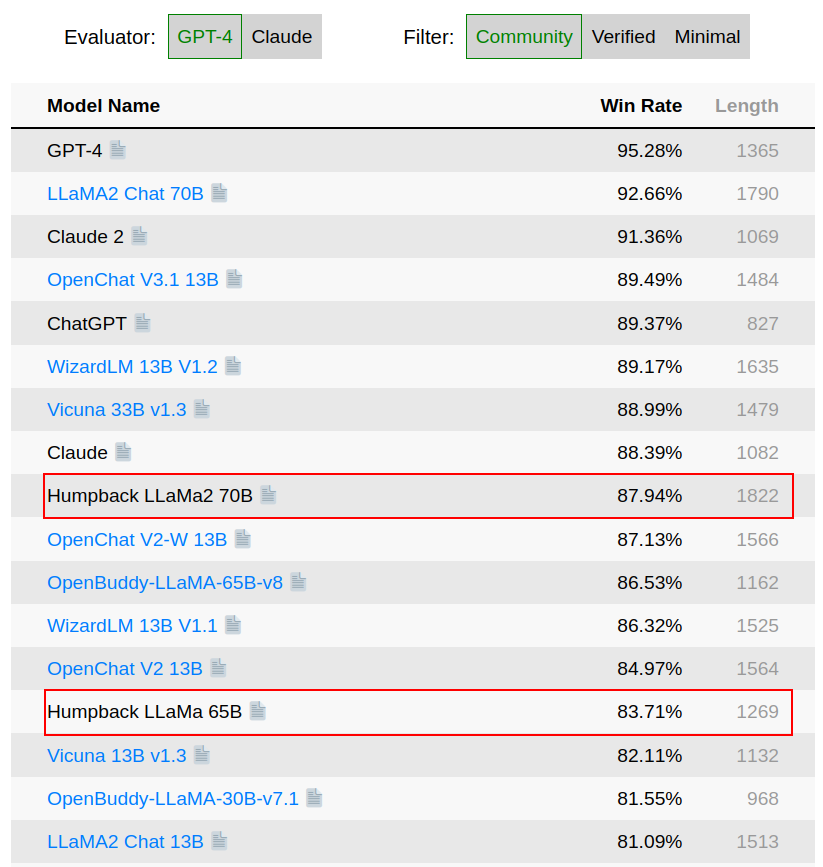
- Humpback osiągnął 83,7% współczynnika zwycięstw (ang. win rate) w benchmarku AlpacaEval, przewyższając wcześniejsze najlepsze wyniki modeli takich jak Guanaco (71,8%) i LIMA (62,7%), które wykorzystują więcej danych adnotowanych ręcznie.
- Przy użyciu zaledwie 3200 przykładów, Humpback osiąga wydajność zbliżoną do zastrzeżonych modeli takich jak Claude. Świadczy to o wysoce efektywnym uczeniu się z małej ilości przykładów.
- Analiza pokazuje, że różnorodność generowanych instrukcji doskonale uzupełnia dane wprowadzone przez ludzi. Iteracyjna selekcja jest kluczowa dla sukcesu.
Wpływ
Technika ta może znacząco obniżyć koszty anotacji potrzebne do rozwijania zdolnych LLMs. W miarę jak modele stają się bardziej biegłe w wykonywaniu instrukcji, mogą się one doskonalić z mniejszym udziałem człowieka.
Wyniki sugerują również, że LLM mają pewną zdolność do samooceny i kontroli jakości, gdy są odpowiednio pobudzane. Może to otworzyć drogę do samodzielnego uczenia się modeli w szerszym zakresie.
Autorzy zwracają jednak uwagę na potencjalne problemy związane ze wzmocnieniem uprzedzeń, bezpieczeństwem i możliwościami przy ustrukturyzowanych danych wyjściowych. Potrzebne jest rygorystyczne testowanie, aby odpowiedzialnie wdrożyć takie systemy.
Podsumowując, „instruction backtranslation” otwiera fascynujący nowy rozdział dla dostrojonych LLMs. Jeśli techniki takie jak ta będą skutecznie skalowane, możemy być świadkami samodzielnego doskonalenia modeli, przy jednoczesnym szacunku dla ludzkich preferencji. Przyszłość pełnych możliwości, pomocnych asystentów opartych na AI wydaje się coraz bardziej realna.