WizardMath: Usprawnianie modeli językowych w rozumowaniu matematycznym
Zespół badaczy z Microsoftu i Shenzhen Institute of Advanced Technology opracował nową metodę o nazwie Reinforced Evol-Instruct, która znacząco usprawnia zdolności rozumowania matematycznego dużych modeli językowych (LLM). Metoda została przedstawiona w nowej pracy „WizardMath: Usprawnianie rozumowania matematycznego dużych modeli językowych za pomocą Reinforced Evol-Instruct„.
Badacze zastosowali Reinforced Evol-Instruct, aby zwiększyć wydajność Llama-2, open-source’owego LLM od Meta z 70 miliardami parametrów. Powstały model, nazwany WizardMath, osiąga najlepsze na świecie wyniki w testach rozumowania matematycznego GSM8k i MATH, przewyższając nawet starsze modele komercyjne, takie jak ChatGPT 3 od OpenAI, PaLM od Google i Claude 1 od Anthropic.
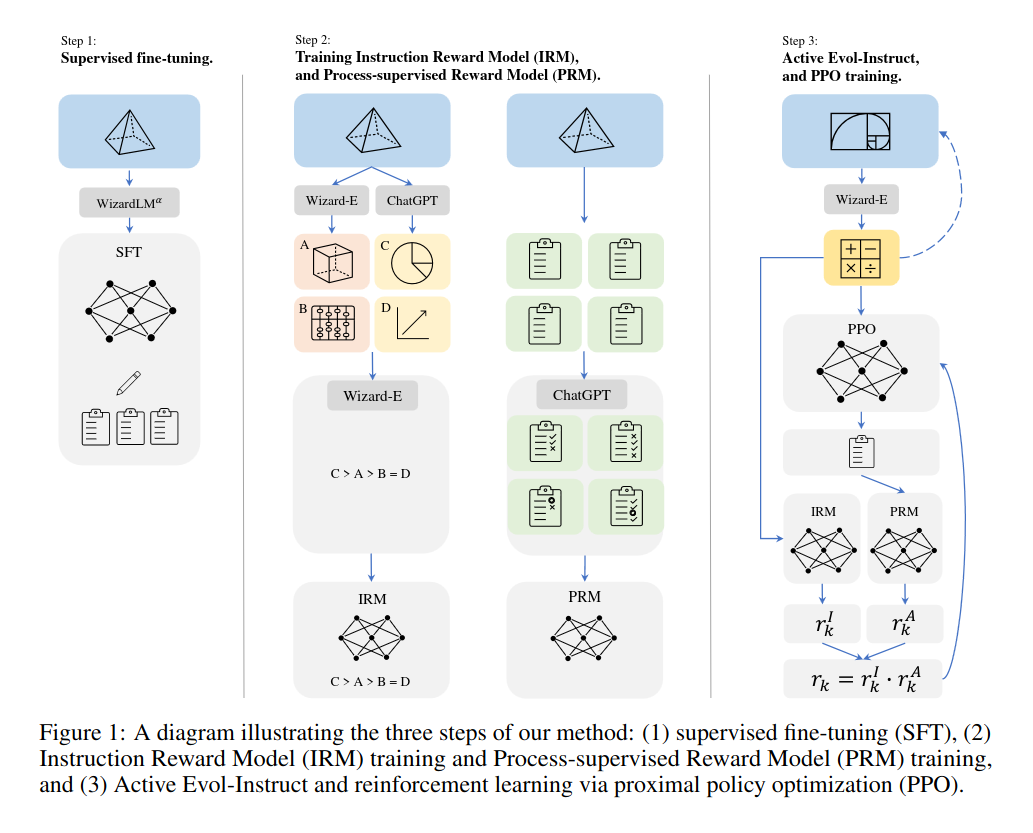
Reinforced Evol-Instruct to nowatorska technika zaproponowana przez badaczy w celu usprawnienia zdolności rozumowania matematycznego dużych modeli językowych (LLM) takich jak Llama-2. Składa się ona z trzech głównych kroków:
- Nadzorowane dostrajanie: LLM jest najpierw dostrajany na problemach i rozwiązaniach matematycznych, aby dostosować go do zadania rozumowania matematycznego.
- Trenowanie modeli nagrody (ang. reward model): Trenowane są dwa modele nagród – model nagród instrukcji, który ocenia jakość pytań matematycznych oraz model nagród procesu, który dostarcza informacji zwrotnej dla każdego kroku rozwiązania.
- Aktywny Evol-Instruct: Pytania matematyczne są iteracyjnie rozwijane w celu zwiększenia zróżnicowania i złożoności, wykorzystując dwie techniki – ewolucję w dół do uproszczenia pytań oraz ewolucję w górę do zwiększenia trudności. Następnie LLM jest trenowany za pomocą uczenia ze wzmocnieniem (ang. Reinforcement Learning) z wykorzystaniem nagród z obu modeli.
W teście GSM8k, zawierającym problemy matematyczne na poziomie szkoły podstawowej, WizardMath-70B-V1.0 osiągnął dokładność 81,6%, ustępując czołowym własnościowym modelom takim jak GPT-4 na poziomie 92%, Claude 2 z wynikiem 88% i Flan-PaLM 2 na poziomie 84,7%, ale przewyższając powszechnie używane modele, takie jak ChatGPT na poziomie 80,8%, Claude Instant z wynikiem 80,9% i PaLM-2 na poziomie 80,7%, przy czym wszystkie te modele są znacząco większe. Najlepszy dotąd open source’owy LLM, Llama-2, uzyskał 56,8%. W bardziej zaawansowanym zbiorze danych MATH, WizardMath osiągnął wynik 22,7% w porównaniu do 19,1% dla davinci-002 od OpenAI. Autorzy opublikowali również dwie dodatkowe wersje modelu z 13B i 7B parametrami.
Znaczący wzrost w stosunku do innych modeli open source i komercyjnych podkreśla skuteczność Reinforced Evol-Instruct. Poprzez ewoluowanie różnorodnych przykładów matematycznych i rozwiązań do treningu modelu oraz wykorzystanie nagród instrukcji i procesu, metoda produkuje modele znacznie lepsze w rozumowaniu matematycznym.
Badacze sugerują, że WizardMath może mieć szerokie zastosowanie w edukacji, zasilając narzędzia, które pomagają uczniom uczyć się i ćwiczyć pojęcia matematyczne. Może również umożliwić budowanie chatbotów podających krok po kroku rozwiązania zadań matematycznych. Ponadto, dostępność WizardMath jako modelu open source sprawia, że najnowsze osiągnięcia w rozumowaniu matematycznym są dostępne dla innych badaczy i programistów.
Podsumowując, artykuł na temat WizardMath demonstruje skuteczne połączenie ewoluowanych instrukcji i uczenia wzmacniania w celu usprawnienia zdolności rozumowania LLM. Zaproponowane techniki dostarczają cennego schematu do dalszego ulepszania modeli językowych w rozumowaniu matematycznym i logicznym.