
OpenOrca przewyższa osiągnięcia Orki z badania Microsoftu
Zespół OpenOrca zaprezentował nowy model językowy o nazwie OpenOrca x OpenChat-Preview2-13B. Jest to model transformer oparty na architekturze LLaMA, wytrenowany na zestawie danych stworzonym na wzór datasetu wykorzystanego do trenowania Orki – modelu stworzonego przez naukowców z Microsoft Research.
Główne osiągnięcia prezentowane w publikacji to:
– Model OpenOrca x OpenChat osiągnął średnio 103% wyników Orki w testach reasoningowych BigBench-Hard i AGIEval, przy użyciu mniej niż 1/10 mocy obliczeniowej i mniej niż 20% danych treningowych w porównaniu do Orki.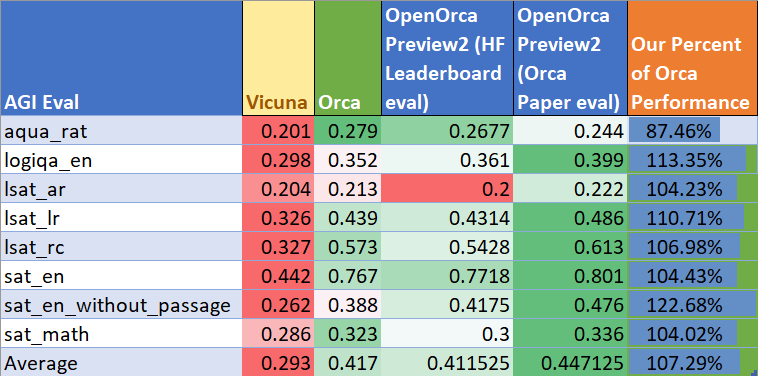
– OpenOrca x OpenChat uzyskał najlepsze wyniki spośród modeli 13B parametrów w rankingach HuggingFaceH4 Open LLM Leaderboard i GPT4ALL Leaderboard.
– Do treningu wykorzystano autorski szablon promptów OpenChat Llama2 V1, co pozwoliło na sprawne uczenie modelu przy niewielkich zasobach obliczeniowych.
Te rezultaty pokazują, że niewielkie zespoły badawcze mogą skutecznie konkurować z korporacjami w dziedzinie uczenia maszynowego, dzięki otwartym frameworkom takim jak HuggingFace i wydajnym technikom uczenia jak OpenChat MultiPack algorithm. Sukces OpenOrca może zainspirować kolejnych naukowców do publikowania swoich osiągnięć jako modeli open source. W dalszej perspektywie, pojawienie się coraz lepszych publicznie dostępnych modeli językowych może przyspieszyć postęp w zakresie sztucznej inteligencji ogólnej.