
Deep Learning w e-commerce
W marcu 2017 roku pracownicy działu badawczego Flipkart, praktycznie nieznanego w Europie „Indyjskiego Amazon” wycenianego na 12 miliardów USD, opublikowali pracę zatytułowaną Deep Learning based Large Scale Visual Recommendation and Search for E-Commerce. Pokazali w niej bardzo ciekawe zastosowanie Deep Learningu do budowy systemu rekomendacyjnego odnajdującego identyczne lub bardzo podobne ubrania na podstawie zdjęcia. Nie jest to pomysł nowy, sami autorzy pracy odwołują się w niej do co najmniej kilkunastu innych prac obejmujących to zagadnienie. Tym razem jednak rozwiązanie zostało zaprojektowane z myślą o e-commerce a nie jako akademicki test możliwości ML więc jego celem było nie tyle stwierdzenie czy dwa prezentowane zdjęcia pokazują tę samą garderobę ile wyszukanie w ogromnej bazie asortymentu przedmiotów podobnych i prezentacja ich jako sugestii dla klienta.
Katalog Flipkarta zawiera, bagatela, 50 milionów produktów odzieżowych a jego zmienność to ok 100 tysięcy operacji insert/delete na godzinę! Wynika to z faktu iż za pomocą Flipkart, podobnie jak w przypadku Amazon handel prowadzi także bardzo wielu innych sprzedawców. Rozwiązanie które zaprojektowali badacze składa się z trzech równolegle działających sieci o identycznych parametrach. Zadaniem modelu jest minimalizacja funkcji Hinge Loss (znanej np. z SVM) czyli innymi słowy maksymalne oddalenie od próbki testowej q próbki negatywnej n przy jednoczesnym maksymalnym zbliżeniu odległości do próbki pozytywnej p.
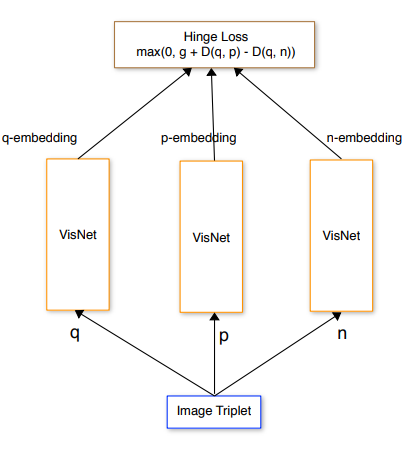
Model uczono na tripletach: próbka testowa, próbka pozytywna (inne ujęcie tego samego produktu) oraz próbka negatywna. 30% próbek negatywnych to tzw. in-class negatives, czyli produkty podobne a 70% to out of class negatives czyli produkty zupełnie inne jednak nadal w tej samej kategorii, np. koszula dla koszul, but dla butów itd.

Każda z sieci na wyjściu generuje embedding w postaci wektora w 4096 wymiarowej przestrzeni, który odzwierciedla cechy analizowanego produktu. Wektory te można następnie wykorzystać do wyszukiwania identycznych bądź podobnych produktów w istniejącej bazie. Mimo iż skuteczność modelu w rozpoznawaniu tripletów wynosiła aż 97.38% to jednak wyszukanie konkretnego produktu w bazie na podstawie zdjęcia jest znacznie niższa.
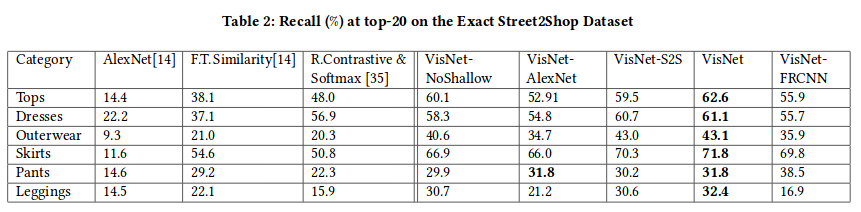
Nawet dla najlepszych modeli (które z powodów wydajnościowych okazały się niepraktyczne) częstość odnalezienia dokładnie tego samego produktu wśród aż 20 pierwszych wyników wynosiła pomiędzy 30 a 60%. Oznacza to, że tylko w jednym-dwóch na 3 przypadki dokładnie dopasowany produkt w ogóle pojawiał się w top 20!

Jak widać w znacznej części przypadków znalezienie dokładnie tego samego produktu jest praktycznie niemożliwe. Wynika to w głównej mierze z ogromu asortymentu i różnorodności wzornictw.
Czy to jednak źle? Co to oznacza w praktyce? Żeby to zbadać autorzy pracy śledzili współczynnik konwersji (CVR – czyli jak często dochodziło do transakcji w wyniku wykorzystania rekomendacji) dla produktów rekomendowanych przez swój system. Dla klasycznych algorytmów opartych o słowa kluczowe i oceny użytkowników CVR we Flipkart wynosiło 8-10% dla systemu opartego na rozpoznawaniu obrazu aż 26%. To nawet 2 do 3 razy więcej! Łatwo sobie wyobrazić jak wpływa to na wielkość sprzedaży.
Wykorzystanie 4096 wymiarowych wektorów kodujących cechy powoduje że do przeszukania przestrzeni ~50 milionów produktów potrzebne są ogromne moce obliczeniowe. Trzeba wyliczyć embeddingi dla nowo dodawanych obiektów, usunąć z bazy te dla produktów usuwanych ale też przeliczyć odległości pomiędzy wszystkimi kombinacjami produktów! Oczywiście zastosowano szereg optymalizacji, odległości liczone są pomiędzy produktami tylko w tej samej klasie (koszulki z koszulkami ale też t-shirtami, koszulami itp, buty z butami, spodnie ze spodniami itd.) ale mimo wszystko nadal potrzebne są do tego całe farmy komputerów. Serwery wyliczające wektory kodujące cechy (Worker) odpalane są w cloud w zależności od potrzeb. Przepływem danych (Ingestion pipeline) zarządza Apache Storm a za najbardziej zasobożerną część, czyli wyliczenie odległości i znalezienie rekomendacji z wykorzystaniem alogrytmu k-NN, odpowiada klaster Hadoop. Próby wykorzystania szybszych ale mniej dokładnych algorytmów, jak Locality Sensitive Hashing (LSH) znacząco pogorszyły rezultaty i ostatecznie nie zostały zaimplementowane.
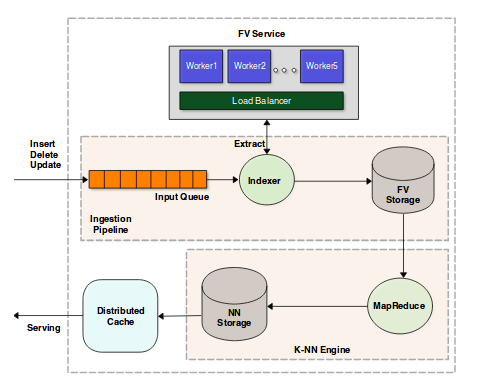
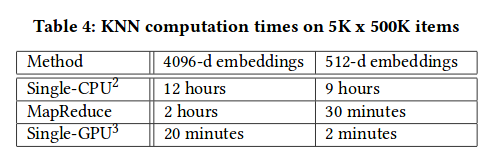
Ze względu na wymaganą mocy obliczeniową ostatecznie na produkcji zaimplementowane zostało mniej optymalne (ok 2%) rozwiązanie wykorzystujące 512 wymiarowe embeddingi. Poniżej czasy przeliczania kNN dla 5 tysięcy nowych produktów vs 500 tyś. z bazy. Warto pamiętać, że że katalog zawiera 50 milionów a w ciągu godziny pojawia się pomiędzy 50 a 100 tyś. nowych produktów.
Rozwiązanie oprócz rekomendacji zostało też wykorzystane do wyeliminowania duplikatów (są one albo wstawiane bezwiednie albo specjalnie w celu zwiększenia ekspozycji przez sprzedawców).
Jak widać Deep Learning ma bardzo szerokie zastosowania, nie tylko w autonomicznych samochodach, wykrywaniu raka płuc, czy zamienianiu koni w zebry 🙂 ale także w handlu elektronicznym. Udowodnili to badacze z Flipkart publikując część stworzonego przez siebie kodu na licencji opensource.