
Przykład klasyfikacji polskich tekstów (część 1)
Klasyfikacja tekstów wydaje się być zagadnieniem akademickim ma jednak bardzo wiele praktycznych zastosowań. Jedno z nich to automatyczne segregowanie zleceń w systemie CRM, innymi przykładami mogą być przypisywanie kategorii i tagów do różnego rodzaju publikacji, np. książek w sklepie, czy artykułów w Internecie, wykrywanie tekstów o określonej treści, np. wulgarnych, nacechowanych nienawiścią, tzw. fake-newsów, czy wręcz rozpoznawanie płci autora, grupy docelowej itd. itp. Wszystko zależy od pomysłowości i dostępnych danych.
Z klasyfikacją tekstów wiąże się też kilka pokrewnych zagadnień o których mam nadzieję w przyszłości napisać. Przykładem mogą być tu określenie wieku autora, roku publikacji, stopnia zdenerwowania piszącego, wartości oceny produktu której towarzyszył komentarz itp. Kolejnym zagadnieniem jest generowanie tekstów na podstawie tekstów: streszczenia na podstawie książki, tematu na podstawie treści zgłoszenia czy wręcz odpowiedzi na zapytanie.
W dalszej części opiszę prosty przykład klasyfikacji tekstów z wykorzystaniem regresji logistycznej w scikit-learn a w przyszłości może pokażę jak można poprawić rezultaty z wykorzystaniem bardziej zaawansowanych technik. Wszystkie przykłady były uruchomione z wykorzystaniem Jupytra kernelem Python 3. Link do notatnika znajduje się na końcu artykułu.
Wybór i pobranie danych
Do zaprezentowania klasyfikacji tekstów niezbędnym elementem są oczywiście same teksty. Ponieważ z oczywistych względów nie mogłem oprzeć przykładów na tekstach które są poufne (a do tej kategorii zaliczają się np. zgłoszenia w systemach CRM) do wykorzystania zostały tylko publicznie dostępne treści. Ponieważ zależało mi na tym aby teksty były polskie oraz łatwo dostępne zdecydowałem się na publikacje w serwisie wolneletury.pl. Zadanie będzie polegało na ustaleniu nazwiska autora na podstawie jednego zdania.
W pierwszym kroku należy pobrać treści książek oraz podzielić je na pojedyncze zdania i oczywiście do każdego zdania przypisać autora. Wybór padł na następujące publikacje oraz autorów:
book_files={
"Mickiewicz": [
"https://wolnelektury.pl/media/book/txt/pan-tadeusz.txt",
"https://wolnelektury.pl/media/book/txt/dziady-dziady-widowisko-czesc-i.txt",
"https://wolnelektury.pl/media/book/txt/dziady-dziadow-czesci-iii-ustep-do-przyjaciol-moskali.txt",
"https://wolnelektury.pl/media/book/txt/ballady-i-romanse-pani-twardowska.txt",
"https://wolnelektury.pl/media/book/txt/ballady-i-romanse-powrot-taty.txt",
"https://wolnelektury.pl/media/book/txt/ballady-i-romanse-switez.txt",
"https://wolnelektury.pl/media/book/txt/dziady-dziady-poema-dziady-czesc-iv.txt",
],
"Sienkiewicz": [
"https://wolnelektury.pl/media/book/txt/quo-vadis.txt",
"https://wolnelektury.pl/media/book/txt/sienkiewicz-we-mgle.txt",
"https://wolnelektury.pl/media/book/txt/potop-tom-pierwszy.txt",
"https://wolnelektury.pl/media/book/txt/potop-tom-drugi.txt",
"https://wolnelektury.pl/media/book/txt/potop-tom-trzeci.txt",
],
"Orzeszkowa": [
"https://wolnelektury.pl/media/book/txt/orzeszkowa-kto-winien.txt",
"https://wolnelektury.pl/media/book/txt/nad-niemnem-tom-pierwszy.txt",
"https://wolnelektury.pl/media/book/txt/nad-niemnem-tom-drugi.txt",
"https://wolnelektury.pl/media/book/txt/nad-niemnem-tom-trzeci.txt",
"https://wolnelektury.pl/media/book/txt/gloria-victis-dziwna-historia.txt",
"https://wolnelektury.pl/media/book/txt/z-pozogi.txt",
"https://wolnelektury.pl/media/book/txt/pani-dudkowa.txt",
"https://wolnelektury.pl/media/book/txt/dymy.txt",
"https://wolnelektury.pl/media/book/txt/syn-stolarza.txt",
"https://wolnelektury.pl/media/book/txt/dobra-pani.txt",
"https://wolnelektury.pl/media/book/txt/cnotliwi.txt",
"https://wolnelektury.pl/media/book/txt/kilka-slow-o-kobietach.txt",
"https://wolnelektury.pl/media/book/txt/patryotyzm-i-kosmopolityzm.txt",
"https://wolnelektury.pl/media/book/txt/julianka.txt",
],
"Prus": [
"https://wolnelektury.pl/media/book/txt/lalka-tom-drugi.txt",
"https://wolnelektury.pl/media/book/txt/lalka-tom-pierwszy.txt",
"https://wolnelektury.pl/media/book/txt/antek.txt",
"https://wolnelektury.pl/media/book/txt/katarynka.txt",
"https://wolnelektury.pl/media/book/txt/prus-anielka.txt",
"https://wolnelektury.pl/media/book/txt/prus-placowka.txt",
],
"Reymont": [
"https://wolnelektury.pl/media/book/txt/ziemia-obiecana-tom-pierwszy.txt",
"https://wolnelektury.pl/media/book/txt/chlopi-czesc-pierwsza-jesien.txt",
"https://wolnelektury.pl/media/book/txt/reymont-chlopi-zima.txt",
"https://wolnelektury.pl/media/book/txt/chlopi-czesc-trzecia-wiosna.txt",
"https://wolnelektury.pl/media/book/txt/chlopi-czesc-czwarta-lato.txt",
]
}
Wybrane pliki pobierzemy do katalogu data. Do pobrania wykorzystałem bibliotekę eventlet która pozwala na zrównoleglenie intensywnych operacji IO (w tym wypadku pobierania danych z Internetu) z wykorzystaniem tzw. zielonych wątków (green threads). Jest to technika którą w pythonie implementuje się z wykorzystaniem tzw. współprogramów (coroutines).
def fetch(url):
file_path = os.path.join("data",os.path.basename(url))
if os.path.exists(file_path):
return None, None
data = request.urlopen(url).read()
return file_path, data
for author in book_files:
pool = eventlet.GreenPool()
for file_path, data in pool.imap(fetch, book_files[author]):
if file_path:
with open(file_path, mode="wb") as f:
f.write(data)
print ("DONE")
Wstępna obróbka i analiza
Tak pobrane pliki z książkami musimy podzielić na zdania, które będziemy wykorzystywać do budowy klasyfikatora. Przy okazji dokonamy ich wstępnej obróbki: zamienimy litery na małe, usuniemy ewentualne znaki specjalne, nadmiarowe spacje itp. Jest to często spotykany jednak dość arbitralny sposób postępowania który w sposób nieodwracalny usuwa z dokumentów (w założeniu mało istotne) informacje. Jako ćwiczenie pozostawię zbadanie wpływu sposobu obróbki na ostateczne rezultaty.
# output corspus file with one sentence per line
def preprocess_file(file_path=None, file_url=None):
if not file_path and file_url:
file_path = os.path.join("data",os.path.basename(file_url))
text = open(file_path,'rb').read().decode("utf-8").lower()
text = regex.sub(u"[^ \n\p{Latin}\-'.?!]", " ",text)
text = regex.sub(u"[ \n]+", " ", text) # Squeeze spaces and newlines
text = regex.sub(r"----- ta lektura.*","", text) # remove footer
return [regex.sub(r"^ ","",l) for l in regex.split('\.|,|\?|!|:',text)]
def get_book_df(document, author):
return pd.DataFrame({
'author': pd.Series(len(document)*[author]),
'txt': pd.Series(document),
})
book_lines_df = pd.concat([
get_book_df(preprocess_file(file_url=url),author=author)
for author in book_files for url in book_files[author]
])
book_lines_df.head()
Sprawdźmy ile mamy zdań dla poszczególnych autorów:
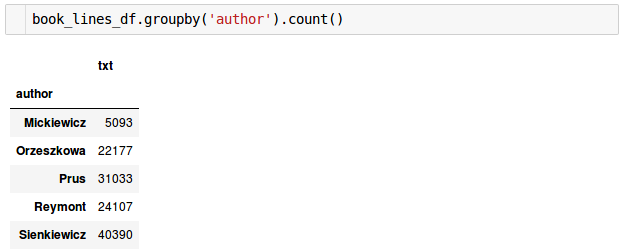
Jak widać liczby te dość mocno się różnią. Jest to ważna informacja gdyż niezrównoważone klasy mają znaczny wpływ na rezultaty osiągane przez wiele klasyfikatorów. Zanotujmy tę informację aby ją później wykorzystać. Obejrzyjmy też statystyki dotyczące ilości wyrazów w zdaniu.
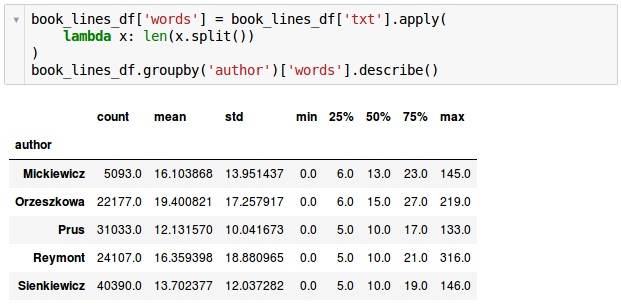
Pierwsza obserwacja jest taka, że niektóre zdania mają zerową długość. Trzeba je więc usunąć. Kolejną jest ciekawostka że Prus miał bardzo spójny styl, najniższą średnią długość zdania (12.13 wyrazów) i najniższe odchylenie standardowe (nie był tez zwolennikiem długich zdań – najdłuższe miało „zaledwie” 133 wyrazy podczas gdy u Reymonta było prawie 2 i pół raza dłuższe. Podobnie wygląda też kwestia na 98 percentylu:
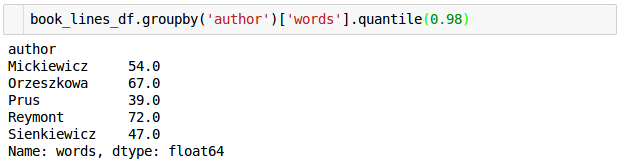
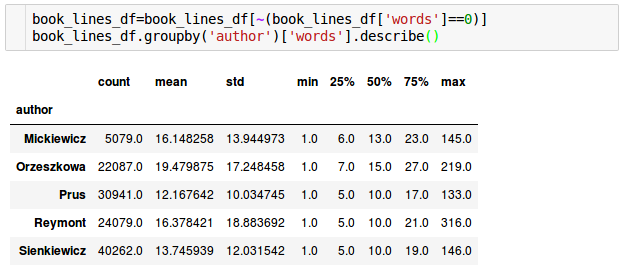
Wystarczy ciekawostek, posprzątajmy dane i weźmy się za przygotowanie modelu.
Ekstrakcja cech i budowa modelu
Jednym z najprostszych sposobów na przeprowadzenie klasyfikacji tekstów jest wykorzystanie regresji logistycznej. Zanim jednak zabierzemy się do budowy naszego modelu nie zapomnijmy o podzieleniu naszych danych na testowe i treningowe abyśmy mogli zweryfikować wyniki na danych out of sample. Do trenowania wykorzystamy 90% danych, resztę pozostawimy do przetestowania końcowego modelu. Przy okazji ważna uwaga, ponieważ chcemy zachować w zbiorach wynikowych proporcje pomiędzy klasami takie jak w danych źródłowych wykorzystamy stratyfikację, czyli najpierw podzielimy zbiór źródłowy na oddzielne zbiory dla każdego autora, na każdym z nich oddzielimy po 10% na zbiór testowy a następnie połączymy odpowiednie części z powrotem. Oczywiście na zakończenie oba zbiory (które formalnie w naszej implementacji są przechowywane jako lista, mają więc ustaloną kolejność) potasujemy. Na szczęście wszystkie te operacje wykona za nas funkcja: sklearn.model_selection.train_test_split
train_df, test_df = train_test_split(
book_lines_df,
test_size=0.1,
stratify=book_lines_df['author'],
)
Skoro mamy już podzielone dane to pozostaje pytanie, jak wprowadzimy nasz tekst do modelu matematycznego? W Machine Learningu zagadnienie to nosi nazwę Feature Extraction i Feature Engineeringu (istnieje między nimi szereg subtelnych różnic ale odsyłam do definicji gdyż nie będę ich tu teraz objaśniał). Jest to bardzo obszerny temat, powstało nań wiele książek i publikacji, w naszym prostym przykładzie użyjemy jednego z najprostszych możliwych (a jednocześnie niekoniecznie najgorszych) sposobów zamiany tekstu na liczby. W pierwszym kroku zbudujemy słownik składający się ze wszystkich słów występujących w tekście. Następnie w każdej próbce (zdaniu) przypiszemy wektor długości takiej jak liczba unikalnych słów i na każdej pozycji odpowiadającej określonemu słowu umieścimy liczbę odpowiadającą ilości wystąpień danego słowa w próbce. Proste, prawda? Taki wektor, jak łatwo sobie wyobrazić, w większości składa się z zer. Całą tę operację wykonuje za nas jedna funkcja:
sklearn.feature_extraction.text.CountVectorizer
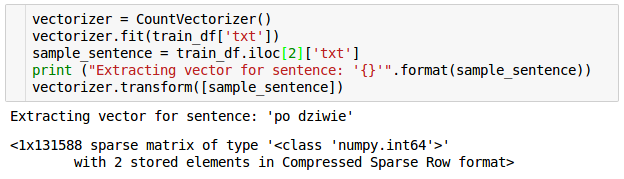
Jak widać przykładowe zdanie, składające się ze 2 wyrazów zostało zapisane jako wektor o długości 131588 elementów. Aby przechować taki obiekt w sposób efektywny w pamięci wykorzystano sparse matrix z 2 elementami. Dzięki temu uniknięto konieczności przechowywania 131586 zer 🙂 Przy okazji kolejna ważna informacja, domyślnie tokenizer jako tokeny traktuje wyrazy o minimum 2 znakach więc wszystkie krótsze słowa (podobnie jak znaki specjalne) zostały zignorowane. W słowniku nie znajdziemy więc „i”, „na”, „od”, „po” itp. Tego typu słowa mają zazwyczaj niewielką wartość jeśli chodzi o klasyfikację (występują z podobnym prawdopodobieństwem we wszystkich rodzajach tekstów).
Jak zapewne zauważyliście do budowy słownika wykorzystałem tylko zbiór treningowy. Dla czego nie cały? Otóż jeśli jakieś słowo występuje wyłącznie w zbiorze testowym nie ma sensu dodawać go do słownika gdyż cecha ta i tak nie stanie się elementem modelu. Ponieważ model nic nie wie na temat tego słowa z danych treningowych nie będzie w stanie żadnej informacji wykorzystać mimo iż zostanie ona zakodowana w wektorze wejściowym.
Skoro mamy już sposób kodowania zdań na liczby, przekształćmy nasze dane, stwórzmy model regresji logistycznej i przeprowadźmy jego dopasowanie („trenowanie” nie byłoby tu właściwym słowem gdyż jest to proces deterministyczny).
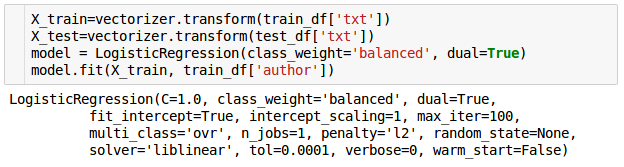
Pierwsze dwie operacje zamieniają nasze teksty na zbiory wektorów wejściowych. Słowo wyjaśnienia należy się linii trzeciej w której tworzymy model regresji logistycznej. Pierwszy z parametrów pomaga zrównoważyć nierównomierne ilości tekstów poszczególnych autorów przypisując im wagi odwrotnie proporcjonalne do częstotliwości występowania danej klasy. Drugi pozwala na wewnętrzne wykorzystanie innego sposobu implementacji algorytmu regresji logistycznej, który jest znacznie szybszy jeśli liczba cech przewyższa ilość próbek (w naszym przypadku mamy 131588 słów w słowniku, czyli kodowanych cech oraz 110520 zdań zbiorze treningowym).
Mając gotowy, dopasowany model sprawdźmy jego jakość na danych testowych:

Wynik 76% wydaje się być całkiem niezły biorąc pod uwagę że wykorzystaliśmy jeden z najprostszych sposobów kodowania danych, jeden z najprostszych modeli klasyfikacyjnych a to wszystko na domyślnych ustawieniach. Wyobraźmy sobie że sami stajemy przed takim zadaniem i na podstawie zaledwie kilki słów, do tego w losowej kolejności (model zna tylko ilość wystąpień, nie zna kolejności słów!), musimy określić do którego z 5 autorów należy. Nie wygląda to na proste zadanie. Jako ćwiczenie dla czytelników pozostawię weryfikację wyników dla zdań o określonej minimalnej długości (zarówno w zbiorze treningowym jak i testowym!).
Trzeba też pamiętać, że accuracy bardzo często nie jest dobrą miarą oceny jakości modelu. Bez wchodzenia w zbyt wiele detali nadmienię że podobnie jest w naszym przypadku. Jako przykład niech posłużą bardziej szczegółowe wyniki miar precision, recall (inaczej sensitivity, czułość), i F1 dla poszczególnych klas:
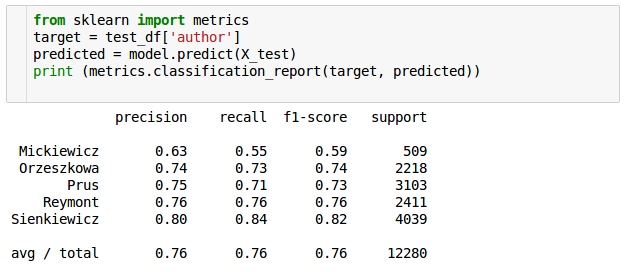
Widać wyraźnie że najgorzej rozpoznawane są zdania Mickiewicza, który był najsłabiej reprezentowany. Tylko w 55% były one prawidłowo rozpoznane (czułość), z 63% precyzją. Najlepiej, oczywiście, model radzi sobie z Sienkiewiczem dla którego mieliśmy najwięcej próbek.
W następnej części postaram się opisać kilka sposobów na poprawienie powyższych rezultatów zarówno po stronie cech jak i modelu, pokażę jak możemy połączyć etapy obróbki danych i budowy modelu w jeden proces oraz postaram się napisać odrobinę więcej na temat sposobów ewaluacji modelu.
Cześć, dzięki wielkie za artykuł i z niecierpliwością czekam na kontynuację 🙂
Mam jedno pytanie o tekst po listingu z tworzenia modelu. W linii „Słowo wyjaśnienia należy się linii trzeciej w której tworzymy model regresji liniowej.” chodzi faktycznie o regresję liniową czy to przejęzyczenie i chodziło o logistyczną?
Oczywiście chodziło o logistyczną. Bardzo dziękuję za zwrócenie uwagi.
Panie Mariuszu,
kiedy można się spodziewać kolejnej części ?
Jak tylko znajdę chwilę wolnego czasu to powinna się pojawić 🙂
Hejka! Będzie ciąg dalszy, czy jednak brak czasu?
Super artykuł i baaaardzo by się przydała kolejna część 🙂
Bardzo bym chciał bo taki był plan, niestety ostatnio krucho z czasem.
Szkoda 🙁
To jest to czego szukałem w necie, i na dodatek ładnie po polsku. Panie Mariuszu, tu jest literówka czekam na dalsze wpisy
https://prnt.sc/nphdih
Bardzo dziękuję za dobre słowo i znalezioną literówkę. Już poprawiona.