
Meta AI wypuściło Code Llama, rodzinę dużych modeli językowych przeznaczonych do obsługi kodu
Meta AI wypuściło Code Llama, rodzinę dużych modeli językowych przeznaczonych do obsługi kodu, która według autorów ustanawia nowy state-of-the-art wśród modeli open source pod względem generowania kodu.
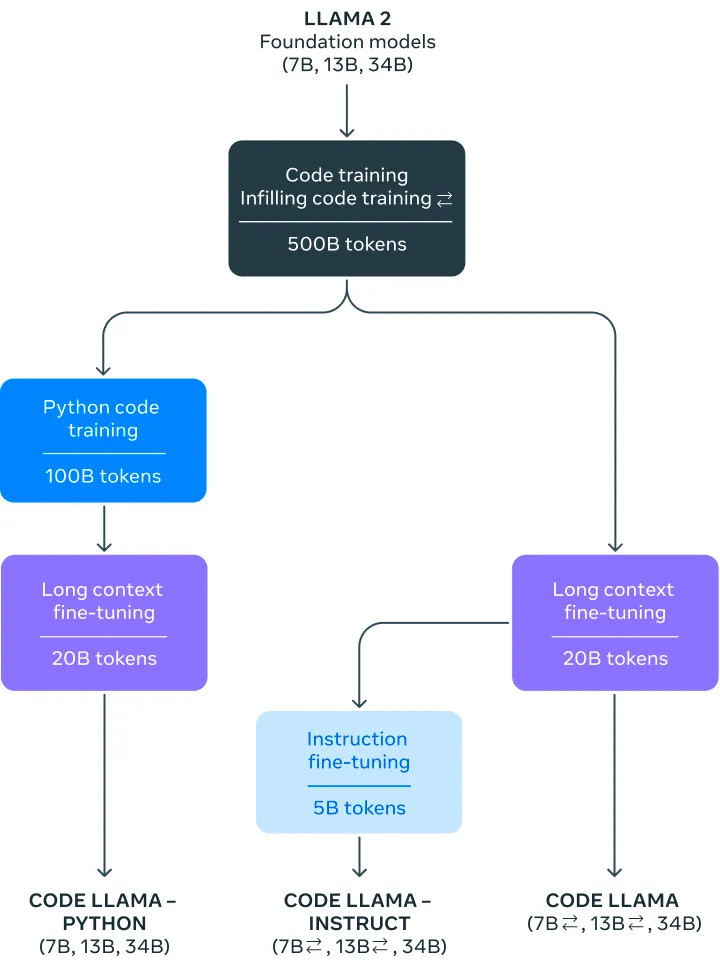
Bazując na modelach bazowych Llama 2, rodzina Code Llama występuje w trzech rozmiarach – 7 mld, 13 mld i 34 mld parametrów – oraz trzech głównych wariantach: Code Llama, Code Llama-Python i Code Llama-Instruct.
Proces Szkolenia
Proces szkolenia i dostosowywania modeli Code Llama można streścić w następujący sposób:
- Inicjalizacja: Modele Code Llama startują z wag modeli podstawowych Llama 2, które zostały wstępnie przeszkolone na 2 bilionach tokenów tekstu i kodu.
- Trenowanie w Kodowaniu: Bazowe modele Llama 2 są trenowane na dodatkowych 500 miliardach tokenów pochodzących w większości z publicznych repozytoriów kodu. Specjalizuje je to do zadań związanych z kodem.
- Szkolenie w uzupełnianiu (ang. infilling): Modele 7B i 13B Code Llama są trenowane z celami wielozadaniowymi, które zawierają wypełnianie zamaskowanych fragmentów kodu, umożliwiając zastosowania takie jak automatyczne uzupełnianie kodu.
- Strojenie do Długiego Kontekstu: Wszystkie modele przechodzą dodatkowe dostosowanie, aby obsługiwać konteksty do 100 000 tokenów poprzez modyfikację osadzeń pozycyjnych (ang. positional embeddings).
- Specjalizacja Pythona: Warianty Code Llama – Python są dodatkowo specjalizowane poprzez szkolenie na 100 miliardach tokenów głównie kodu Pythona.
- Strojenie do Instrukcji: Wreszcie modele Code Llama – Instruct są dostosowywane poprzez strojenie na mieszance instrukcji ludzkich oraz wygenerowanych w celu poprawy bezpieczeństwa, użyteczności i prawdziwości.
Kluczowe Osiągnięcia
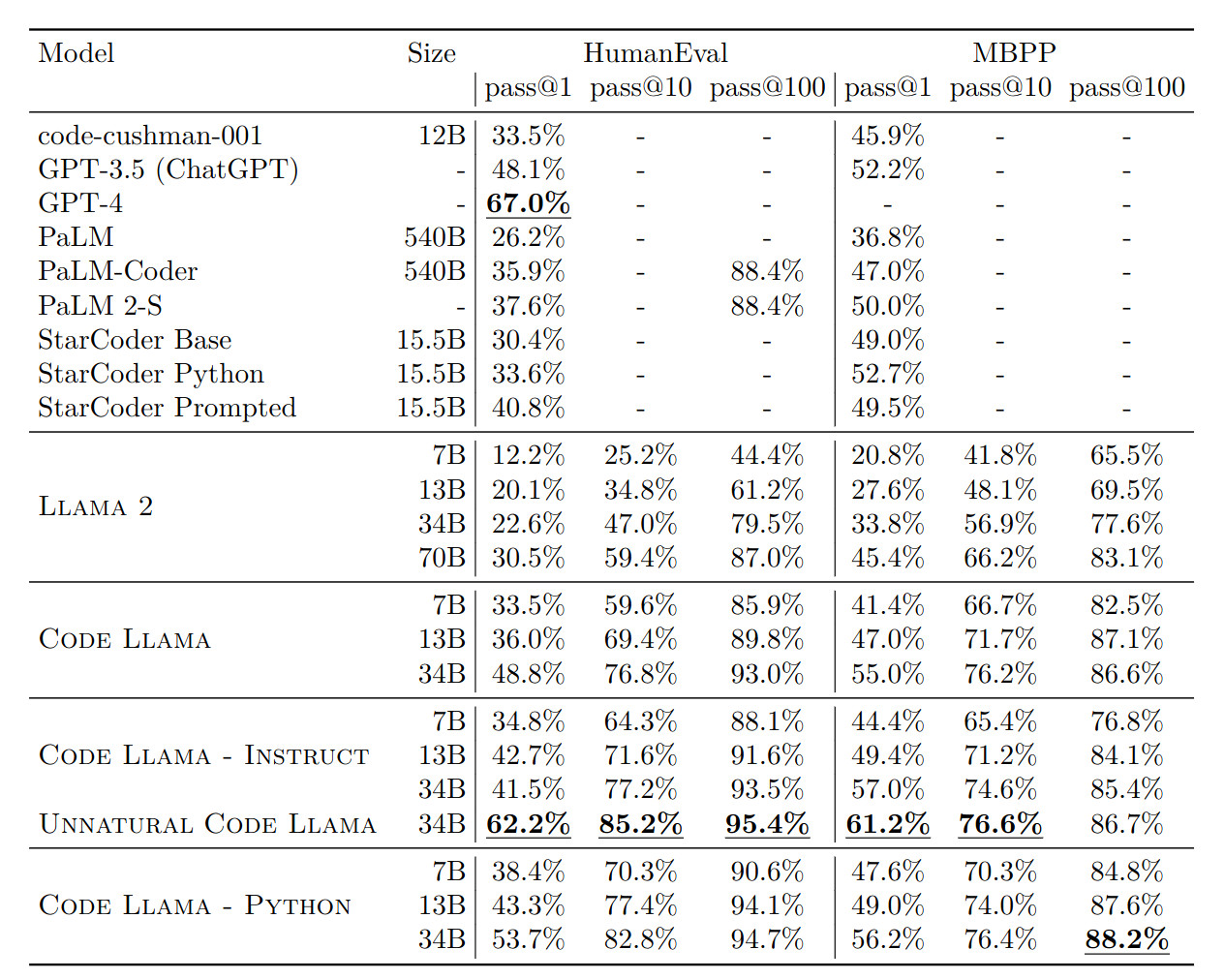
Model 34B Code Llama osiąga wynik 48,8% na benchmarku HumanEval dotyczącym generowania kodu na podstawie opisów w naturalnym języku. Jest to najwyższy wynik spośród otwartych modeli, przewyższając również modele takie jak PaLM Coder (36%) czy GPT-3.5 (ChatGPT – 48,1%).
Na benchmarku MBPP, Code Llama 34B osiąga wynik 55% dla pass@1, ponownie będąc najlepszym wynikiem wśród modeli otwartych. Wielojęzyczna wersja, Code Llama-Instruct 34B, osiąga najlepsze wyniki pass@1 wśród modeli publicznych dla 6 języków programowania w benchmarku MultiPL-E.
Code Llama również demonstruje zdolność do obsługi długich kontekstów wejściowych do 100 000 tokenów, co może odblokować możliwość wnioskowania na temat całych repozytoriów kodu. Mniejsze wersje 7B i 13B dodatkowo obsługują generowanie tekstu poprzez wypełnianie.
Modele Unnatural
W celach porównawczych Meta dostroiła również model Code Llama – Python 34B na 15 000 nienaturalnych instrukcjach podobnie jak w pracy Honovich i wsp. (2023). Meta nie udostępniła tego modelu, ale zaobserwowała wyraźną poprawę w testach HumanEval i MBPP, wskazując na możliwości poprawy osiągów przy niewielkim zestawie wysokiej jakości danych programistycznych.
Modelem nienaturalnym nazywany jest model językowy, który był fine-tuneowany na nienaturalnych danych, czyli danych sztucznie wygenerowanych w celu poprawy wydajności modelu w określonych zadaniach.
Główne cechy danych nienaturalnych to:
- Nie są one napisane przez ludzi w celach naturalnej komunikacji.
- Są one generowane algorytmicznie, często przy użyciu tego samego modelu lub innego modelu.
- Podążają za bardzo konkretnymi wzorcami lub szablonami dostosowanymi do uzyskania wysokich wyników na benchmarkach.
Celem korzystania z danych nienaturalnych jest szybka poprawa umiejętności modelu w określonych dziedzinach, takich jak programowanie, bez konieczności kosztownego oznaczania danych przez ludzi. Jednak modele dostosowane w ten sposób mogą tracić zdolności ogólnego zrozumienia języka.
Dostosowywanie za pomocą danych nienaturalnych budzi kontrowersje, ponieważ dane te nie reprezentują naturalnego języka, a optymalizacja wyłącznie pod kątem benchmarków może prowadzić do osobliwego zachowania modelu. Niemniej jednak pozostaje to aktywnym obszarem badań w celu szybkiego dostosowywania modeli do nowych zadań.
Konsekwencje
Rodzina modeli Code Llama otwiera nowe możliwości dla asystentów AI, narzędzi do autouzupełniania i syntezujących używanych przez programistów. Poprzez udostępnienie Code Llama na zasadach zbliżonych do open-source, Meta ma na celu stymulowanie postępów w dziedzinie AI dla programowania.
Mocne wyniki modelu w zadaniach generowania kodu mogą prowadzić do bardziej płynnej pracy programistów w IDE i innymi narzędziami developerskimi. Wielojęzyczność Code Llama może poszerzyć zakres obsługiwanych języków.
Możliwość wykorzystania długich kontekstów potencjalnie pozwala na podsumowywanie lub wyszukiwanie informacji w całych repozytoriach kodu. To mogłoby pomóc w wykrywaniu błędów, tworzeniu dokumentacji i nawigacji po dużych repozytoriach kodu i „legacy codebase”.